
Organizations operate in an environment where data has become their most valuable asset. The speed, reliability, and scalability of data transfer directly influence business competitiveness, especially in industries such as finance, e-commerce, cloud computing, and IoT. Traditional data transfer mechanisms, such as scheduled batch processing or file-based delivery, often struggle to meet the demands of real-time analytics, high concurrency, and rapid scalability. This is where Apache Kafka, an open-source distributed event streaming platform, has revolutionized the way businesses move and process information.
Apache Kafka is designed to handle high-throughput, fault-tolerant, and low-latency data pipelines. It functions as a distributed publish–subscribe messaging system capable of processing millions of messages per second without performance degradation. In modern architectures, Kafka is central in enabling continuous data integration across microservices, streaming analytics, and hybrid cloud environments.
For companies managing critical workloads, Kafka ensures uninterrupted data flow between systems, applications, and services, regardless of scale. Its resilience and scalability make it ideal for handling high-volume, mission-critical operations.
Furthermore, Kafka has become a foundation for building real-time analytics systems and enterprise cloud hosting strategies.
How Apache Kafka Works for High-Throughput Data Streaming
Apache Kafka’s architecture is built to optimize data ingestion, storage, and distribu at scale. At its core, Kafka uses a publish–subscribe model where the producer
Kafka’s scalability is achieved through topics, which distribute data across multiple brokers. Each broker can handle a portion of the workload, enabling different infrastructure setups to continue operating without hitting performance limits.
A distinguishing factor is Kafka’s commit log storage mechanism, where data is written to disk sequentially. This architecture makes Kafka a transport mechanism and a durable storage layer for streaming data. Combined with integrations into frameworks like Apache Spark, Flink, and Hadoop, Kafka becomes the backbone of enterprise-grade real-time data pipelines, enabling instant insights without the latency penalties of traditional ETL systems.
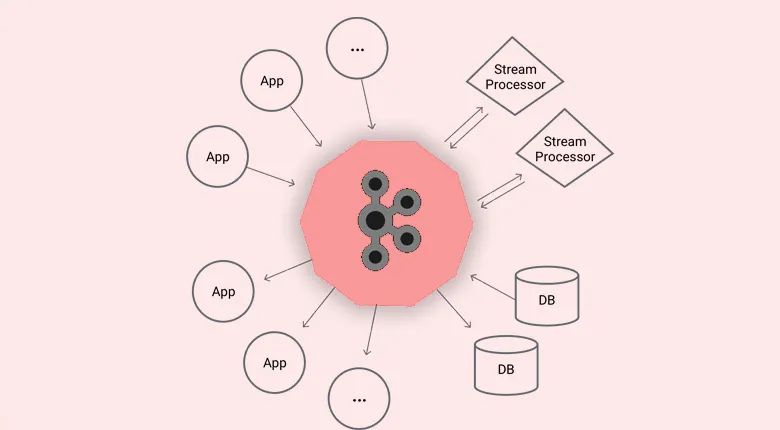
Core Components of Apache Kafka Architecture
Core Components of Apache Kafka Architecture
Apache Kafka’s architecture is composed of several core components that work together to deliver a scalable, fault-tolerant, and high-performance data streaming platform. Understanding these components is crucial for designing an efficient Kafka deployment.
Brokers: Kafka brokers are the backbone of the cluster, responsible for storing and serving data to consumers. Each broker can manage thousands of partitions and handle gigabytes of reads and writes per second. In production environments, deploying multiple brokers ensures high availability and fault tolerance.
Topics and Partitions: Topics act as logical categories where messages are published. To enhance scalability, topics are divided into partitions, which allow multiple consumers to process data in parallel. Partitions also preserve the order of messages within them, an essential feature for transactional data streams.
Producers and Consumers: Producers send data to topics, while consumers subscribe to topics to retrieve data. This decoupling of producers and consumers enables independent scaling, allowing organizations to meet varying workload demands without redesigning their systems.
Zookeeper: Zookeeper manages cluster metadata, broker registration, and leader election for partitions. Although modern versions of Kafka are transitioning to a Zookeeper-less architecture, it remains a critical component in many deployments.
For businesses deploying Kafka, the flexibility of its architecture means it can operate seamlessly in both on-premises and cloud environments. Which One Is Better? The flexibility of its architecture means it can operate seamlessly in both on-premises and cloud environments. This adaptability is one reason Kafka is a preferred choice for mission-critical, high-volume data transfer systems.
Key Advantages of Using Apache Kafka for Data Transfer
Apache Kafka offers numerous advantages that make it the gold standard for real-time, high-volume data pipelines.
High Throughput: Kafka’s ability to process millions of messages per second ensures it can handle workloads of any scale. This is vital for industries such as finance, where milliseconds can mean millions in profit or loss.
Scalability: Kafka’s partitioning mechanism and distributed architecture allow horizontal scaling without downtime. Whether you’re running on Best Dedicated Server Unmetered Bandwidth or a hybrid cloud setup, Kafka can grow with your business needs.
Fault Tolerance: Replication across brokers ensures that data remains available even in the event of node failures.
Durability: Kafka retains messages for a configurable period, enabling replay and ensuring compliance with data retention policies.
Integration Ecosystem: Kafka integrates with tools like Spark, Flink, Hadoop, and Kubernetes, making it suitable for diverse data processing and analytics workflows.
Cost Efficiency: By reducing the complexity of point-to-point integrations, Kafka minimizes maintenance overhead and infrastructure costs.
These benefits make Kafka not just a messaging system but a strategic asset for businesses seeking to modernize their data architecture.
Common Use Cases of Apache Kafka in Enterprises
Common Use Cases of Apache Kafka in Enterprises
Kafka’s versatility makes it a go-to solution across industries:
Financial Services: Real-time fraud detection, stock price monitoring, and transaction analytics. Banks achieve secure, high-speed data transfer between services by integrating Kafka into their core infrastructures.
E-commerce: Synchronizing inventory in real-time, personalizing customer experiences, and enabling instant payment processing.
Telecommunications: Monitoring network performance, processing call detail records, and handling millions of concurrent events.
IoT & Manufacturing: Aggregating data from thousands of devices for predictive maintenance and process optimization.
Media & Entertainment: Streaming analytics for personalized recommendations and real-time user engagement metrics.
In each of these use cases, Kafka’s ability to handle continuous, high-throughput data streams ensures seamless user experiences and operational efficiency.
Real-Time Data Processing with Apache Kafka
Real-time processing is one of Kafka’s defining strengths. Through Kafka Streams, developers can build applications that process and analyze data as it arrives, without the latency of batch processing. This enables instant insights for decision-making.
For example, an e-commerce site can detect spikes in product demand and automatically adjust pricing or stock allocation. In cloud environments, such as those optimized for running a Website on Shared Hosting? Here’s How to Optimize Resource Usage — Kafka ensures that high-volume data flows between application layers without bottlenecks.
By combining Kafka with machine learning pipelines, companies can deliver personalized content, detect security anomalies, and even automate complex operational workflows. The ability to filter, aggregate, and transform data on the fly gives organizations the agility they need to respond instantly to evolving market conditions.
Ensuring Data Reliability and Fault Tolerance in Kafka
Data reliability is a non-negotiable requirement for mission-critical systems. Apache Kafka addresses this by implementing a replication model where each partition has multiple copies stored across different brokers. This ensures that if one broker fails, another broker holding the replica can immediately take over, eliminating single points of failure.
The replication factor is configurable, allowing organizations to strike a balance between fault tolerance and storage costs. For high-value data streams — such as financial transactions or healthcare records — a higher replication factor is often preferred to guarantee maximum availability.
Kafka also uses an acknowledgment mechanism to confirm data delivery. Producers can specify whether they want acknowledgments from the leader broker only, or from all in-sync replicas, depending on the trade-off between latency and durability requirements.
Another critical aspect is Kafka’s log compaction feature, which retains the latest version of each record key indefinitely. This is especially useful for maintaining accurate states in systems where historical values are irrelevant.
When deployed alongside secure and optimized infrastructures, Kafka’s fault tolerance capabilities become a foundation for dependable, large-scale data operations. Enterprises that require 24/7 uptime, such as stock exchanges or telecom providers, rely heavily on these mechanisms to ensure uninterrupted service delivery.
Security Practices for Data Transfer with Apache Kafka
Security Practices for Data Transfer with Apache Kafka
Security in Kafka deployments involves protecting data in transit and at rest, as well as controlling access to sensitive streams.
Encryption with SSL Certificate: Implementing an SSL Certificate ensures that data moving between producers, brokers, and consumers is encrypted. This prevents interception and unauthorized modification during transit.
Authentication: Kafka supports SASL (Simple Authentication and Security Layer) protocols, enabling secure verification of client identities.
Authorization: Access Control Lists (ACLs) determine which clients or applications can read from or write to specific topics.
Network Segmentation and Firewalls: Deploying Kafka within private networks or using virtual private clouds reduces exposure to external threats.
Monitoring and Logging: Continuous monitoring for suspicious activity is essential. Integrating Kafka with SIEM (Security Information and Event Management) tools enables rapid detection and response to security incidents.
By embedding these practices within a secure hosting environment, businesses can protecting sensitive workflows from data breaches and cyberattacks.
Apache Kafka vs RabbitMQ: Detailed Comparison
Apache Kafka and RabbitMQ are both widely used for message brokering, but their architectures and use cases differ significantly.
Performance and Throughput: Kafka is designed for high-throughput, distributed streaming, capable of handling millions of messages per second. RabbitMQ is optimized for low-latency message delivery but struggles at Kafka’s scale.
Message Retention: Kafka stores messages for a configurable period, enabling replay, whereas RabbitMQ deletes messages once consumed (unless explicitly persisted). This makes Kafka more suitable for event sourcing and long-term data pipelines.
Use Cases: RabbitMQ excels in request–response scenarios, short-lived tasks, and systems requiring immediate delivery confirmation. Kafka shines in streaming analytics, real-time monitoring, and large-scale data integration.
Scalability: Kafka’s partitioning model allows horizontal scaling without impacting performance. RabbitMQ can scale, but often requires clustering configurations that are more complex to manage.
For enterprises running Bare Metal Servers vs Virtual Servers: What’s the Difference?, Kafka’s design often proves more resilient under massive workloads, while RabbitMQ may be more cost-effective for smaller-scale, latency-sensitive applications.
Apache Kafka vs RabbitMQ
Performance and Scalability
When it comes to raw performance, Kafka and RabbitMQ are built with very different goals in mind. Kafka was designed from the ground up as a distributed event streaming platform, capable of handling millions of messages per second with predictable latency across clusters of brokers. This makes it extremely effective in environments where large volumes of data need to be processed in real time, such as monitoring platforms or analytics pipelines. RabbitMQ, by contrast, prioritizes lightweight message delivery and simplicity. It handles smaller workloads with low latency, but scaling RabbitMQ to the same level as Kafka requires additional effort in clustering and resource management. For businesses that anticipate rapid data growth or operate across multiple geographic regions, Kafka provides the scalability and resilience needed to maintain performance under heavy load. RabbitMQ, however, remains an excellent choice for smaller, transactional workloads where speed and efficiency outweigh the need for massive scale.
Use Case Suitability
The real decision between Kafka and RabbitMQ often comes down to use case rather than raw technical specs. RabbitMQ is widely adopted for systems that rely on request–response communication or where guaranteed delivery of messages in smaller volumes is the priority. For example, order processing systems, background task queues, or microservices environments often benefit from RabbitMQ’s simplicity and reliability. Kafka, on the other hand, is better suited for architectures where data streams need to be retained, replayed, or processed continuously. Event sourcing, fraud detection, and real-time analytics are strong examples of workloads that thrive on Kafka’s design. The choice of infrastructure also influences suitability: some enterprises host their RabbitMQ clusters on virtualized environments, while others deploy Kafka on high-performance setups such as Bare Metal Servers vs Cloud Servers
. Ultimately, the question is less about which tool is “better” and more about which tool aligns with the operational needs and long-term goals of the business.

Apache Kafka vs FTP
Apache Kafka vs FTP: Why Traditional File Transfer Falls Short
FTP (File Transfer Protocol) has been a staple for moving files between systems for decades. However, its limitations become apparent in modern, data-driven environments.
Speed and Efficiency: FTP operates in batch mode, often requiring manual initiation or scheduled jobs. Kafka streams data continuously, reducing delays from hours to milliseconds.
Reliability: FTP lacks inherent fault tolerance; a failed transfer may require a full restart. Kafka’s replication and acknowledgment systems guarantee data delivery even in the event of node failures.
Scalability: FTP is point-to-point, making large-scale integrations cumbersome. Kafka’s publish–subscribe model allows multiple consumers to process the same stream simultaneously without added overhead.
Security: While FTP can be secured via FTPS or SFTP, Kafka’s SSL-based encryption and ACL-based access control provide more granular and robust protection.
For organizations with modern IT infrastructures, Kafka’s continuous streaming approach aligns far better with the need for real-time analytics and scalability.
Other Alternatives to Apache Kafka
While Apache Kafka is one of the most popular event streaming platforms, it is not the only option available. Two of the most common alternatives are AWS Kinesis and Apache ActiveMQ.
AWS Kinesis: This is Amazon’s fully managed service for real-time data streaming. It offers seamless integration with AWS services, making it attractive for organizations already invested in the AWS ecosystem. Unlike Kafka, Kinesis automatically handles scaling and replication, which reduces operational overhead but can lock businesses into vendor-specific pricing and configurations.
Apache ActiveMQ: A traditional message broker that supports multiple messaging protocols. ActiveMQ is easier to set up than Kafka, but it is more suited for smaller-scale, low-throughput applications where message persistence and order are less critical.
Other tools like Google Pub/Sub, Redpanda, and NATS are also used in specialized environments. Each has its advantages, but when compared to Kafka, they often trade off some combination of scalability, flexibility, or fault tolerance.
For organizations already using high-performance infrastructures such as Best Storage Dedicated Server Hosting or hybrid cloud models, Kafka generally provides the most balanced approach in terms of cost, control, and capability. However, alternatives can make sense for workloads with different requirements, especially if a company’s development team is already familiar with those ecosystems.
Best Practices for Scaling Apache Kafka Deployments
Best Practices for Scaling Apache Kafka Deployments
Scaling Apache Kafka effectively requires a strategy that covers both infrastructure optimization and data management. Partition Strategy: Design partitions based on expected throughput and parallelism needs. Too few partitions limit scalability; too many can increase overhead.
Replication Factor: Choose a replication factor that balances availability and cost. For mission-critical streams, a factor of three is common.
Consumer Lag Monitoring: Regularly check consumer lag to ensure processing keeps pace with incoming data. Tools like Prometheus and Grafana are commonly integrated for visualization.
Broker Resource Allocation: Monitor CPU, disk I/O, and network bandwidth on brokers. Hosting Kafka on optimized environments can prevent performance bottlenecks and ensure smooth data streaming..
Retention Policies: Fine-tune retention times to avoid unnecessary storage costs while maintaining replay capabilities.
Load Testing: Conduct load tests before scaling production workloads to ensure the cluster can handle expected peak loads.
By following these practices, organizations can ensure that Kafka grows with their needs while maintaining performance, reliability, and cost efficiency.
Integrating Apache Kafka with Cloud Hosting Environments
Integrating Kafka into cloud hosting architectures provides flexibility, scalability, and cost advantages. Kafka can run on virtual machines, containerized environments (Docker, Kubernetes), or managed services.
Cloud Server Deployments: Hosting Kafka on Cloud Hosting vs VPS Hosting Benefits and Differences enables elastic scaling, pay-as-you-go billing, and global availability zones for low-latency data delivery.
Hybrid Cloud: Combining on-premises Kafka clusters with cloud instances allows businesses to handle sensitive workloads locally while using the cloud for burst processing or disaster recovery.
Managed Hosting Services: Providers handle Kafka installation, configuration, and monitoring, freeing internal teams to focus on development.
Security in the Cloud: Using private subnets, VPNs, and SSL encryption ensures that Kafka traffic in cloud environments remains secure.
Whether running on public, private, or hybrid infrastructure, Kafka’s ability to integrate seamlessly across these environments makes it a strong fit for businesses undergoing digital transformation.

Monitoring and Troubleshooting Apache Kafka Data Transfers
Monitoring and Troubleshooting Apache Kafka Data Transfers
Proactive monitoring ensures that Kafka’s performance remains consistent under varying workloads.
Key Metrics: Monitor broker CPU usage, disk utilization, partition distribution, and consumer lag. Unbalanced partitions or overloaded brokers can lead to delays in processing.
Tooling: Solutions like Prometheus, Grafana, and Confluent Control Center provide real-time visibility into Kafka metrics. For deeper troubleshooting, Kafka’s built-in logs and JMX metrics are essential.
Common Issues:
Under-replicated Partitions: Indicates replication lag and potential risk of data loss.
High Latency: Often caused by slow consumers or network congestion.
Message Loss: Usually linked to misconfigured acknowledgment settings.
Following structured troubleshooting workflows allows teams to diagnose and resolve problems quickly, minimizing downtime.
Case Studies:
Businesses Leveraging Apache Kafka for Data Transfer
Retail Chain: Integrated Kafka with point-of-sale systems to provide real-time inventory tracking across hundreds of stores. This reduced stockouts by 30% and improved supply chain efficiency.
Banking Institution: Implemented Kafka for fraud detection. Streaming transaction data in real-time allowed AI models to flag suspicious activity within milliseconds, preventing millions in potential losses.
Logistics Provider: Used Kafka to track shipments and vehicle telemetry in real-time. This data was combined with predictive analytics to optimize delivery routes and reduce fuel costs.
In all cases, the organizations benefited from Kafka’s fault tolerance, scalability, and integration flexibility — capabilities that could not be matched by traditional transfer methods like FTP or simple message queues.
Conclusion
Apache Kafka stands out as a high-throughput, fault-tolerant, and scalable platform for modern data transfer. While alternatives like RabbitMQ, FTP, and AWS Kinesis serve specific niches, Kafka’s ability to store, replay, and process massive data streams in real time makes it a strategic choice for enterprises.
For organizations already invested in robust hosting solutions — whether Bare Metal Server vs Cloud Server – Pros and Cons or hybrid cloud setups — Kafka’s architecture ensures seamless integration and reliable operation at any scale.
The decision ultimately depends on workload characteristics, latency requirements, and infrastructure capabilities. However, for most data-driven enterprises aiming for real-time insights and operational agility, Kafka remains the gold standard.
Leave a Reply